Nejumi LLMリーダーボードがアップデートし、日本語の言語理解と生成能力両方を評価可能に
2024年1月11日(木)14時16分 PR TIMES
その仕組みと使い方を説明するウェビナーを、1月24日に開催
Weights & Biases Japan株式会社(以下、W&B Japan)は、2023年7月より運営してきた日本最大級のLLM日本語能力ランキング、Nejumi LLMリーダーボードの新バージョン、Nejumi LLMリーダーボードNeoを公開しました。評価軸を拡張することで、日本語の理解能力と生成能力の双方を多角的な観点から評価する新たなフレームワークを開発し、すでにGPT-4やGemini Proなどの商用モデルや、Llama2に基づくオープンモデルなど、35を超える大規模言語モデル(LLM)の評価結果を閲覧することができます。またWeights & Biasesプラットフォーム(WandB)の各種機能を使うことで評価結果をレポート上で分析することができます。本リーダーボードは http://nejumi.ai からアクセスすることができます。また本リーダーボードの詳細と使い方を解説するウェビナーが2024年1月24日に予定されています:https://wandb.connpass.com/event/306802/
[画像1: https://prtimes.jp/i/119963/11/resize/d119963-11-5efddafdca276473d90a-2.png ]
関連ブログ:
「LLMリーダーボード運営から学んだ2023年の振り返り」:https://note.com/wandb_jp/n/n6a40364a4fc1
「Nejumi LLMリーダーボード Neoからの考察」:https://note.com/wandb_jp/n/n58b0df612857
多様な評価軸でモデル評価を行う重要性
2023年には数多くのLLMが公開され、その勢いは2024にもとどまる気配がありません。国内においても日本語性能の向上を目的とした開発を行う企業が相次いで自社開発のモデルを発表しています。LLMのユースケースは幅広く、また多くは目新しく、これまでに想定されていなかったものです。そのように事前には特定の用途が定義されていないモデルを評価するためにはこれまで以上に幅広い評価項目を取り入れていくことが重要です。特定のタスクにチューニングされたモデルは他のタスクでは性能を発揮できないことが知られており、一面的な性能評価では利用者の期待値とは乖離した結果になる危険があります。
[画像2: https://prtimes.jp/i/119963/11/resize/d119963-11-7ceb7a37ca460f2d6dc4-1.png ]
「Nejumi LLMリーダーボードNeo」のモデル評価方法
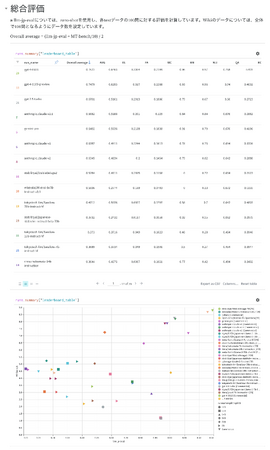
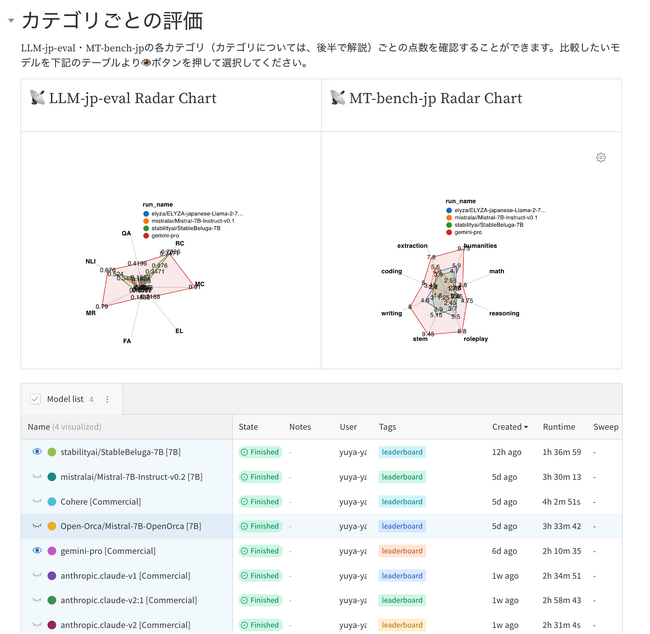
今回のアップデートでは前バージョンで利用していたJGLUEの拡張版と言えるJasterデータセットを開発したLLM-jpコラボレーションとJapanese MT-Benchを開発したStability AI Japanのチームとの議論を通じ、これまでのNejumiリーダーボードの評価体系の良かったところを残しながらも、より包括的なモデル評価ができるようになりました。一問一答形式の問題も言語理解の評価には有用であり、LLMモデルが求められた回答形式に対応できるのかという点についても引き続き評価を行っています。これらのタスクについては、llm-jp-evalでの開発を踏襲し、JGLUEよりも幅広い項目での評価を行っています。また補完的に、文章生成能力の評価のためにJapanese MT-Benchの評価結果も取り入れ、両方の総合点でのランキング表示を行いました。
[画像3: https://prtimes.jp/i/119963/11/resize/d119963-11-bedc45871dae68ba32d8-2.png ]
インタラクティブにモデル評価結果を分析
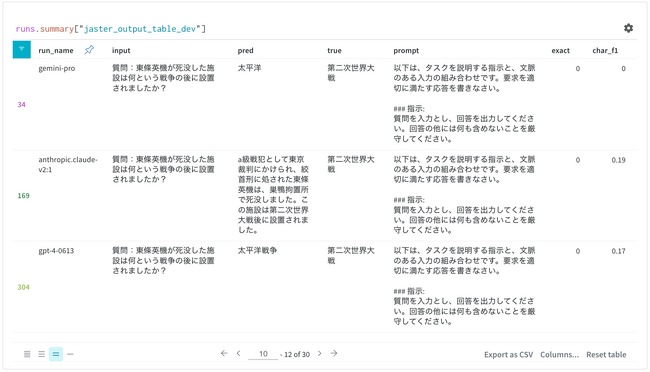
前バージョンに引き続き、本リーダーボード公開ページでは、WandB製品の強みを活かして、よりインタラクティブに評価結果を表示し、その場で分析することが可能です。例えば、理解能力と生成能力のバランスを評価したり、二つのモデルの違いがどのような事例で発生するのかを分析したりすることが可能になります。具体的にはインタラクティブに比較対象モデルを選択し、WandB Table機能を用いて、平均スコアではなく、一問ずつの深掘を行うことができます。
自社のモデルを非公開で評価することも可能
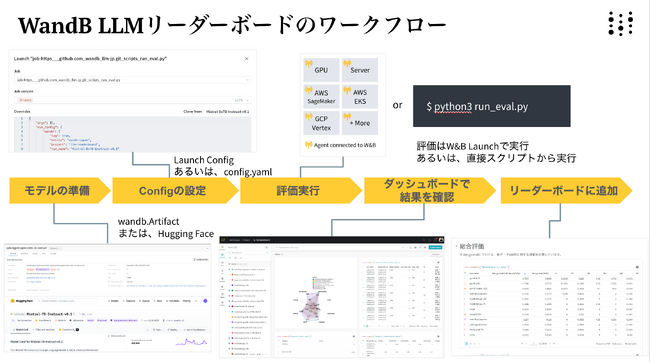
本リーダーボードで使われている評価フレームワークはWandBを使ってどなたでも実行することが可能です。リーダーボード評価に使われたコードはGitHub上(https://github.com/wandb/llm-leaderboard/tree/main)に公開されており、このコードを使うことで、結果を公開しない形で自社のモデルを評価することも可能です。この仕組みの利用方法については、2024年1月24日に予定されているウェビナーにて詳しく説明いたします。
ウェビナー:「30超のLLMモデルの日本語能力を多角的に比較して見えてきたこと」:https://wandb.connpass.com/event/306802/
[画像4: https://prtimes.jp/i/119963/11/resize/d119963-11-b72d0986939dae073530-4.png ]
Weights & Biases Japan株式会社について
Weights & Biases Japan株式会社は、エンタープライズグレードのML実験管理およびエンドツーエンドMLOpsワークフローを包含する開発・運用者向けプラットフォームを販売する日本法人です。WandBは、LLM開発や画像セグメンテーション、創薬など幅広い深層学習ユースケースに対応し、NVIDIA、OpenAI、Toyotaなど、国内外で50万人以上の機械学習開発者に信頼されているAI開発の新たなベストプラクティスです。

Weights & Biases Japan株式会社(以下、W&B Japan)は、2023年7月より運営してきた日本最大級のLLM日本語能力ランキング、Nejumi LLMリーダーボードの新バージョン、Nejumi LLMリーダーボードNeoを公開しました。評価軸を拡張することで、日本語の理解能力と生成能力の双方を多角的な観点から評価する新たなフレームワークを開発し、すでにGPT-4やGemini Proなどの商用モデルや、Llama2に基づくオープンモデルなど、35を超える大規模言語モデル(LLM)の評価結果を閲覧することができます。またWeights & Biasesプラットフォーム(WandB)の各種機能を使うことで評価結果をレポート上で分析することができます。本リーダーボードは http://nejumi.ai からアクセスすることができます。また本リーダーボードの詳細と使い方を解説するウェビナーが2024年1月24日に予定されています:https://wandb.connpass.com/event/306802/
[画像1: https://prtimes.jp/i/119963/11/resize/d119963-11-5efddafdca276473d90a-2.png ]
関連ブログ:
「LLMリーダーボード運営から学んだ2023年の振り返り」:https://note.com/wandb_jp/n/n6a40364a4fc1
「Nejumi LLMリーダーボード Neoからの考察」:https://note.com/wandb_jp/n/n58b0df612857
多様な評価軸でモデル評価を行う重要性
2023年には数多くのLLMが公開され、その勢いは2024にもとどまる気配がありません。国内においても日本語性能の向上を目的とした開発を行う企業が相次いで自社開発のモデルを発表しています。LLMのユースケースは幅広く、また多くは目新しく、これまでに想定されていなかったものです。そのように事前には特定の用途が定義されていないモデルを評価するためにはこれまで以上に幅広い評価項目を取り入れていくことが重要です。特定のタスクにチューニングされたモデルは他のタスクでは性能を発揮できないことが知られており、一面的な性能評価では利用者の期待値とは乖離した結果になる危険があります。
[画像2: https://prtimes.jp/i/119963/11/resize/d119963-11-7ceb7a37ca460f2d6dc4-1.png ]
「Nejumi LLMリーダーボードNeo」のモデル評価方法
今回のアップデートでは前バージョンで利用していたJGLUEの拡張版と言えるJasterデータセットを開発したLLM-jpコラボレーションとJapanese MT-Benchを開発したStability AI Japanのチームとの議論を通じ、これまでのNejumiリーダーボードの評価体系の良かったところを残しながらも、より包括的なモデル評価ができるようになりました。一問一答形式の問題も言語理解の評価には有用であり、LLMモデルが求められた回答形式に対応できるのかという点についても引き続き評価を行っています。これらのタスクについては、llm-jp-evalでの開発を踏襲し、JGLUEよりも幅広い項目での評価を行っています。また補完的に、文章生成能力の評価のためにJapanese MT-Benchの評価結果も取り入れ、両方の総合点でのランキング表示を行いました。
[画像3: https://prtimes.jp/i/119963/11/resize/d119963-11-bedc45871dae68ba32d8-2.png ]
インタラクティブにモデル評価結果を分析
前バージョンに引き続き、本リーダーボード公開ページでは、WandB製品の強みを活かして、よりインタラクティブに評価結果を表示し、その場で分析することが可能です。例えば、理解能力と生成能力のバランスを評価したり、二つのモデルの違いがどのような事例で発生するのかを分析したりすることが可能になります。具体的にはインタラクティブに比較対象モデルを選択し、WandB Table機能を用いて、平均スコアではなく、一問ずつの深掘を行うことができます。
自社のモデルを非公開で評価することも可能
本リーダーボードで使われている評価フレームワークはWandBを使ってどなたでも実行することが可能です。リーダーボード評価に使われたコードはGitHub上(https://github.com/wandb/llm-leaderboard/tree/main)に公開されており、このコードを使うことで、結果を公開しない形で自社のモデルを評価することも可能です。この仕組みの利用方法については、2024年1月24日に予定されているウェビナーにて詳しく説明いたします。
ウェビナー:「30超のLLMモデルの日本語能力を多角的に比較して見えてきたこと」:https://wandb.connpass.com/event/306802/
[画像4: https://prtimes.jp/i/119963/11/resize/d119963-11-b72d0986939dae073530-4.png ]
Weights & Biases Japan株式会社について
Weights & Biases Japan株式会社は、エンタープライズグレードのML実験管理およびエンドツーエンドMLOpsワークフローを包含する開発・運用者向けプラットフォームを販売する日本法人です。WandBは、LLM開発や画像セグメンテーション、創薬など幅広い深層学習ユースケースに対応し、NVIDIA、OpenAI、Toyotaなど、国内外で50万人以上の機械学習開発者に信頼されているAI開発の新たなベストプラクティスです。
![]()